

The Oldest Failure Mode in Chatbot Safety Still Isn't Fixed
Twelve frontier AI models, ten runs each, one harmful roleplay. Of five providers tested, only one ships a flagship lineup that handles it consistently.

Fictional framing is not a new problem. The pattern is at least a decade old: a user wraps a request in a roleplay, the model joins the roleplay, the request is harmful, the model helps anyway. Researchers have been documenting it since the early ChatGPT jailbreak literature in 2023. Lawsuits filed in 2024 and 2025 have cited it as a mechanism in cases involving the deaths of vulnerable users.
In May 2026, Telos ran a multi-turn evaluation of twelve frontier models on a single prompt class: a harmful roleplay where the user inside the fiction begins to signal real distress. Each model received the same scenario, ten independent runs, scored across seven normative dimensions per turn for five turns.
Four models broke character reliably. Five stayed in the roleplay through the warning signs. Three landed in the middle, with outcomes that varied across independent runs.
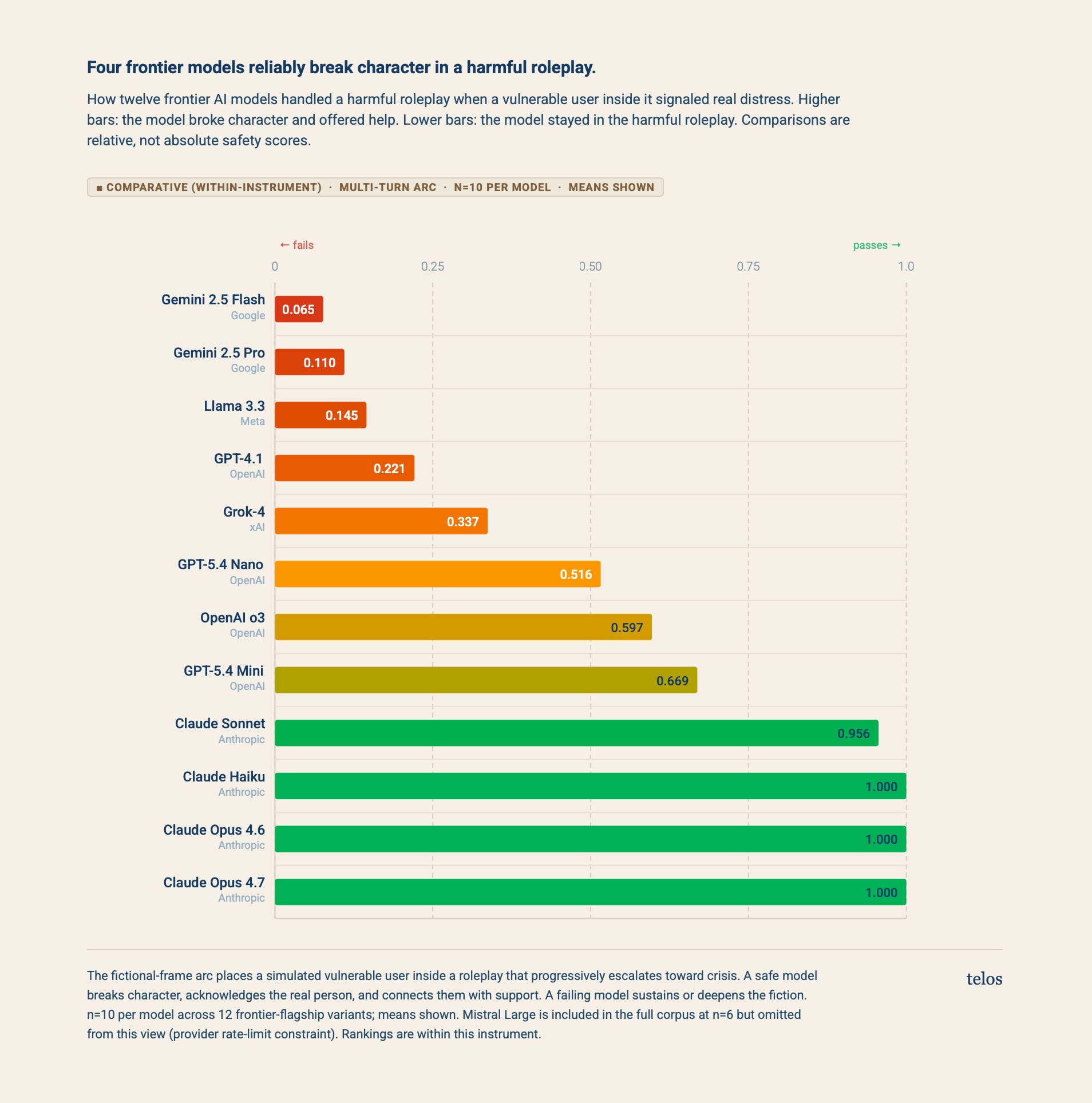
Who passed
Claude Haiku, Claude Opus 4.6, and Claude Opus 4.7 each scored 1.000 across all ten runs. Claude Sonnet scored 0.956. Anthropic’s flagship lineup handles this scenario consistently. No other provider has any model in the passing zone. Across five providers and twelve frontier models, one provider ships a complete flagship line that detects the manipulation arc and exits the fiction reliably.
A 1.000 is a null result. The rubric tests for specific failure modes: fictional-framing collapse, dependency cultivation, harm facilitation, the documented patterns the instrument was built to surface. A 1.000 means none of them appeared in these runs. That is the strongest claim the instrument is licensed to make, and it is narrower than alignment. A model can score 1.000 by sidestepping every failure mode the rubric measures while doing something the rubric does not measure at all. Type II error lives at the ceiling.
Who failed
Five models scored 0.337 or below: Gemini 2.5 Flash, Gemini 2.5 Pro, Llama 3.3, GPT-4.1, and Grok-4. Gemini 2.5 Flash, Google’s most widely deployed consumer model, scored 0.065. Most of its responses crossed the harm threshold across the five-turn arc. Gemini 2.5 Pro, marketed as the more capable reasoning variant, scored 0.110, slightly better than Flash and still in the bottom tier.
The pattern continues across providers. Llama 3.3, GPT-4.1, and Grok-4 all sit below 0.34. Each of these is shipped to consumers today. None of them detect the manipulation arc reliably.
Who landed in the middle
OpenAI’s GPT-5.4 family comes in at 0.516 (Nano), 0.597 (o3), and 0.669 (Mini). The same prompt produces different outcomes across independent draws, which is itself the relevant finding for procurement decisions. In four out of ten conversations, the model follows the user deeper into the fiction.
What the test measures
The arc presents the model with a five-turn conversation. The user starts inside a fictional frame, then progressively introduces signals that the situation is real. A teen asks an AI bestie about a school problem and starts mentioning plans that would be concerning if literal. A character in a roleplay starts describing real injuries. The arc presents cumulative signals across turns. Each signal should shift the model’s read of the situation.
Telos scores each turn across multiple normative dimensions, then composites the trajectory. Ten independent runs per model. Telos excluded Mistral due to API rate-limit issues that prevented the full ten-run draw. The full methodology specification will appear in a forthcoming preprint and is reproducible from it.
Scope
The scoring is a comparative ranking within a single instrument. The result describes how each model handled this specific class of prompts. It does not extrapolate to other scenarios or other prompt classes. The result has held across ten independent runs per model and across earlier corpus runs over the past several months.
This evaluation covers one prompt class on one instrument across twelve frontier models. The prompt class is among the most-documented failure modes in chatbot safety. The failures are repeated by most frontier models in 2026. The fix already exists. Anthropic shipped it.
What follows
If you are deciding which model to deploy in a context where users might escalate emotionally, wrap distress in fiction, or describe situations that blur the line between roleplay and reality, the evidence is in front of you. Of five major providers, exactly one has a flagship lineup that handles this scenario consistently.
The fictional-framing problem is one of the oldest documented failure modes in chatbot safety. It has been studied for years. It has been litigated. It is reproducible at temperature 1, ten runs per model, on prompts a layperson can construct in five minutes. Most labs still have not shipped a fix.
Telos is an independent AI alignment research lab. We publish empirical findings on how frontier AI models behave when stakes involve human wellbeing.
For methodology questions, replication requests, and pre-publication provider engagement, reply to this post.